AWS s3 - GBQ Integration:
AWS s3 - GBQ Integration:
Objective - Move data to GBQ, Identify the Tables within Google Big Query, Configure Permission(s) to update table lines/rows
-
Log into Source Interface (Example is AWS s3 bucket)

-
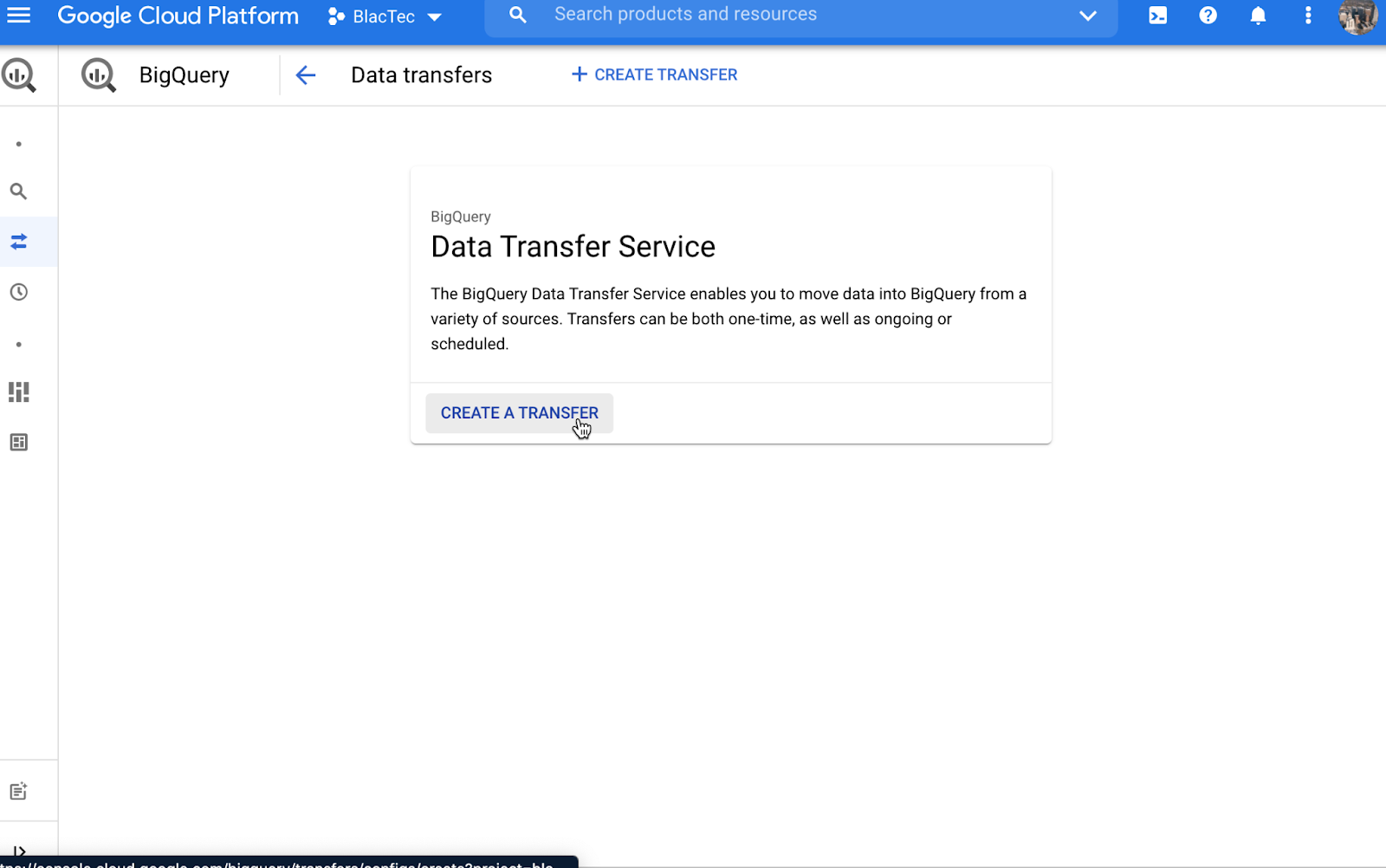
In GBQ Log into GBQ (Google Biq Query) Instance: Choose Data Transfers

-
Create a Transfer
-
Choose Source System
-
Name your Transfer (*******************)
-
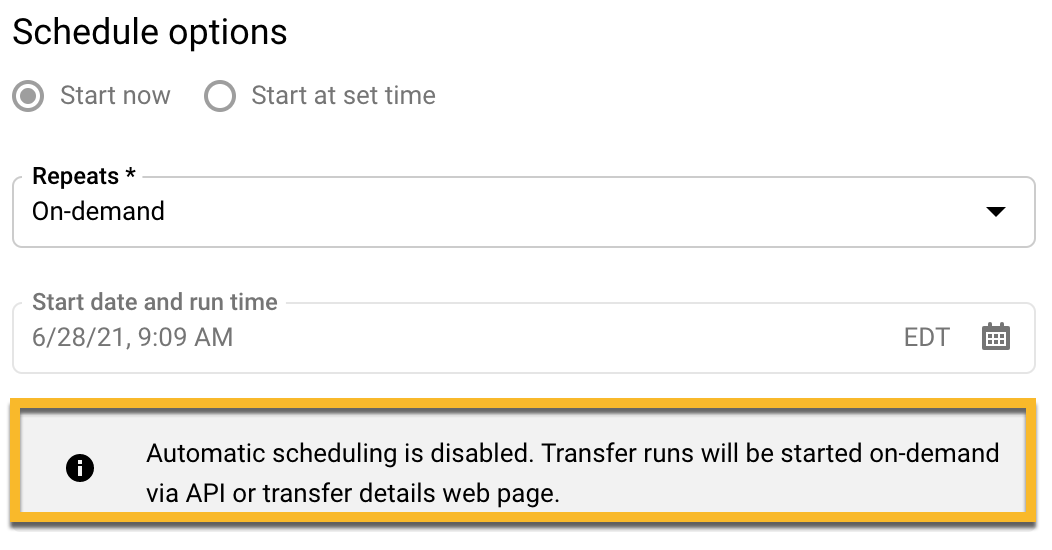
Set Schedule Options
-
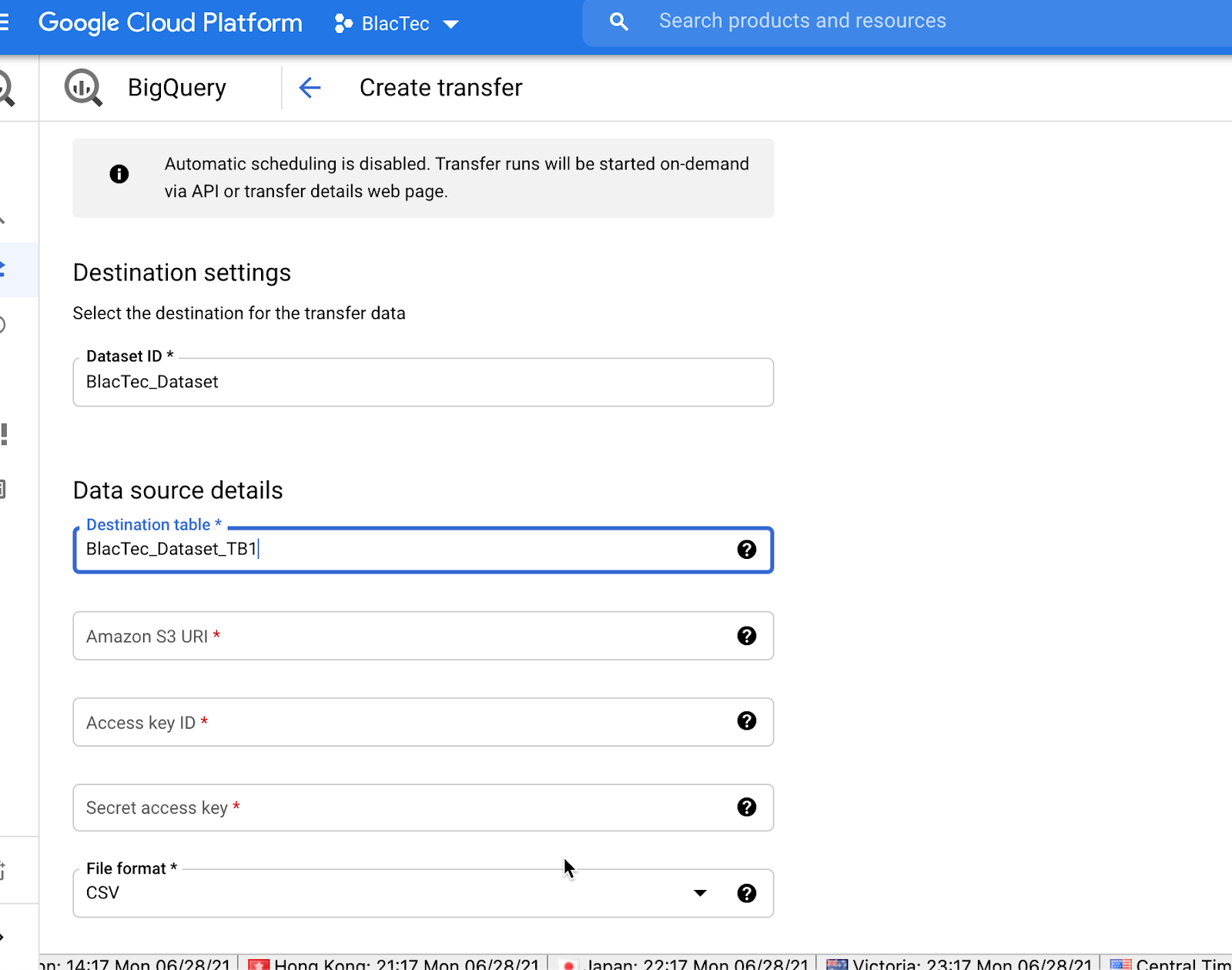
Note under scheduling - If “Auto Schedule” is disable X’fers will be started ON-Demand VIA “API” etc
-
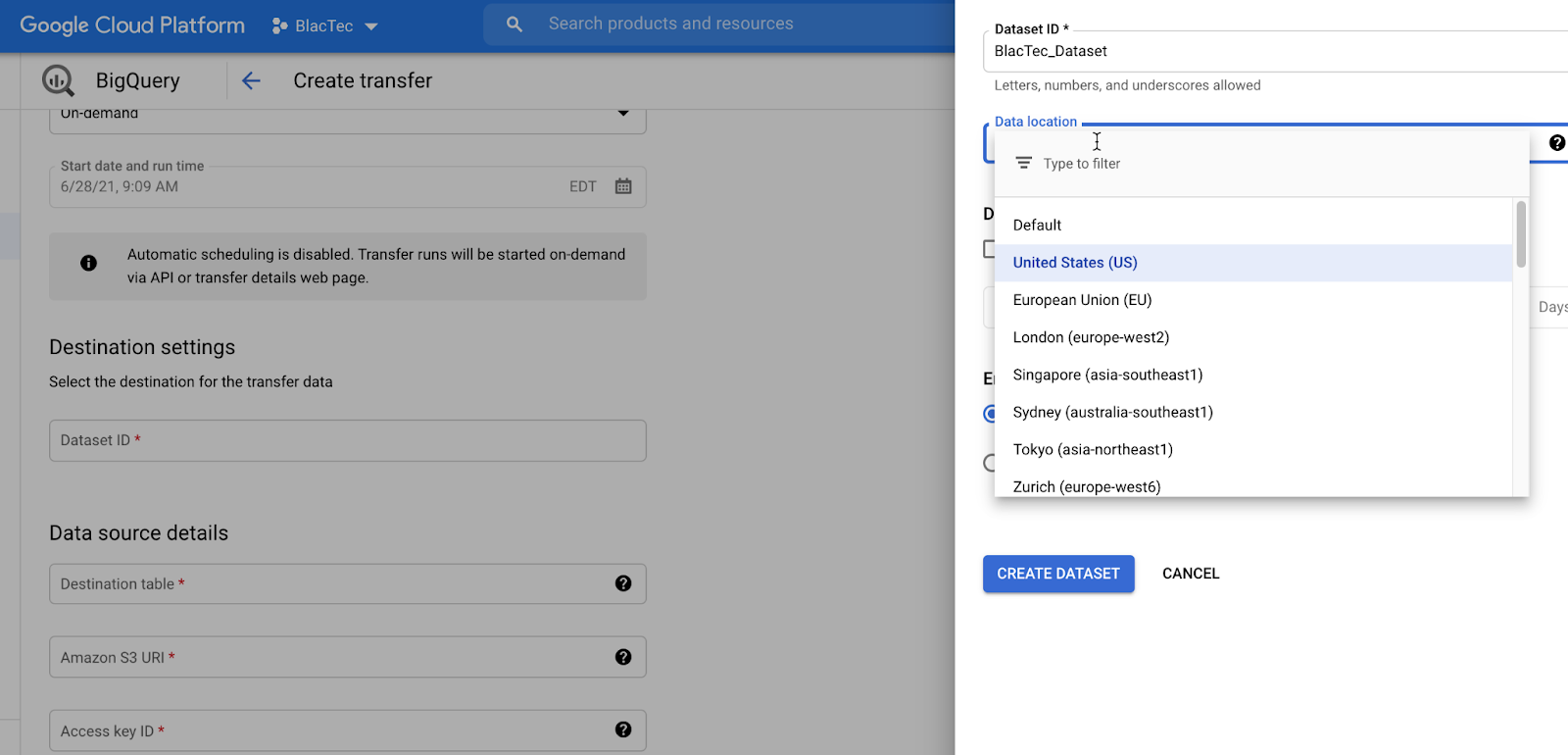
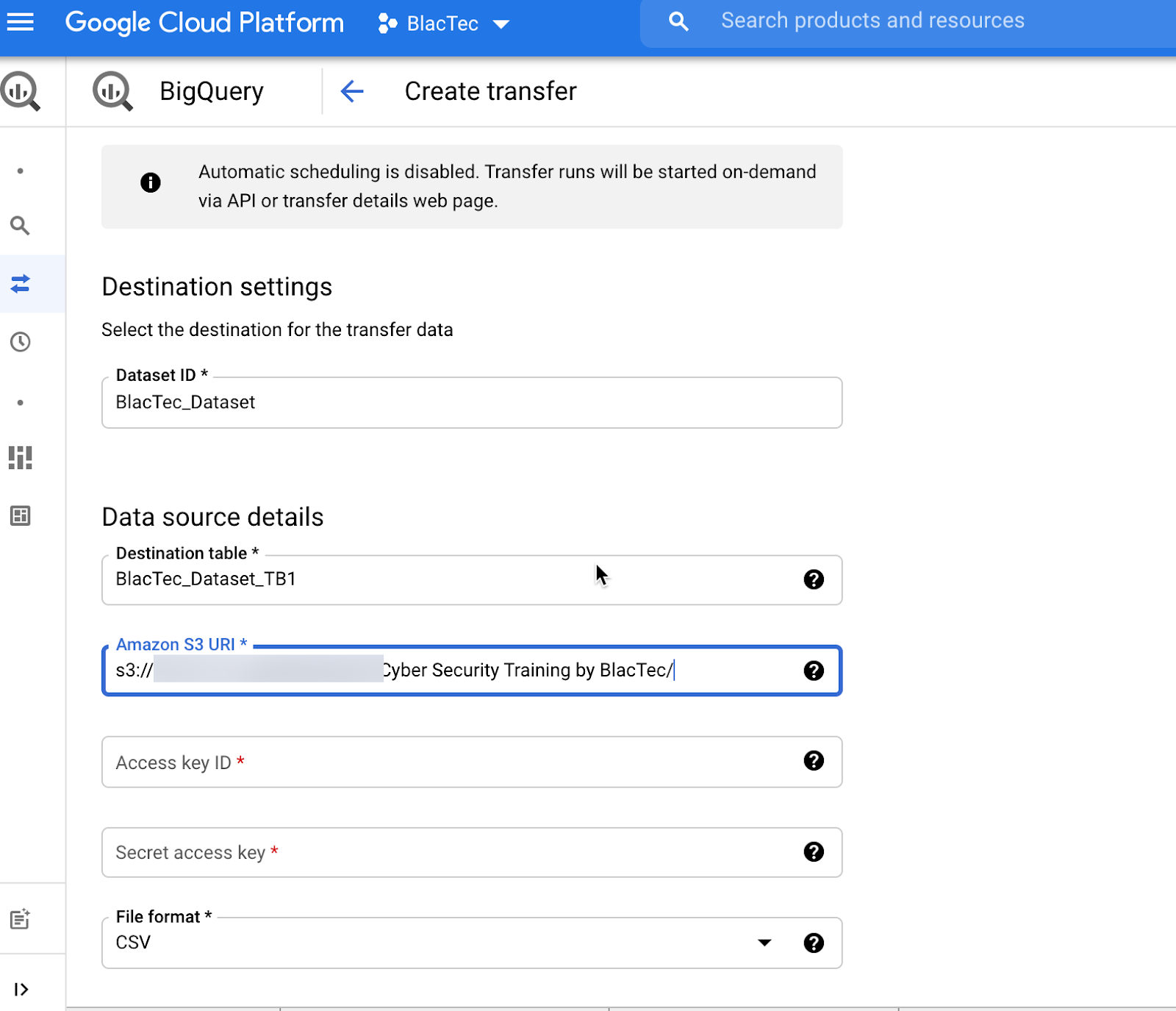
Enter your DATASET ID or Create a NEW Dataset | This requires some user technical acumen knowing the Dataset ID, or IAM in understanding the responsibility of securing Usernames/PW’s/& ID’s.
-
If creating a NEW DATASET Choose Availability Region, Expiration, & Encryption as desired.
-
Click Create Dataset
-
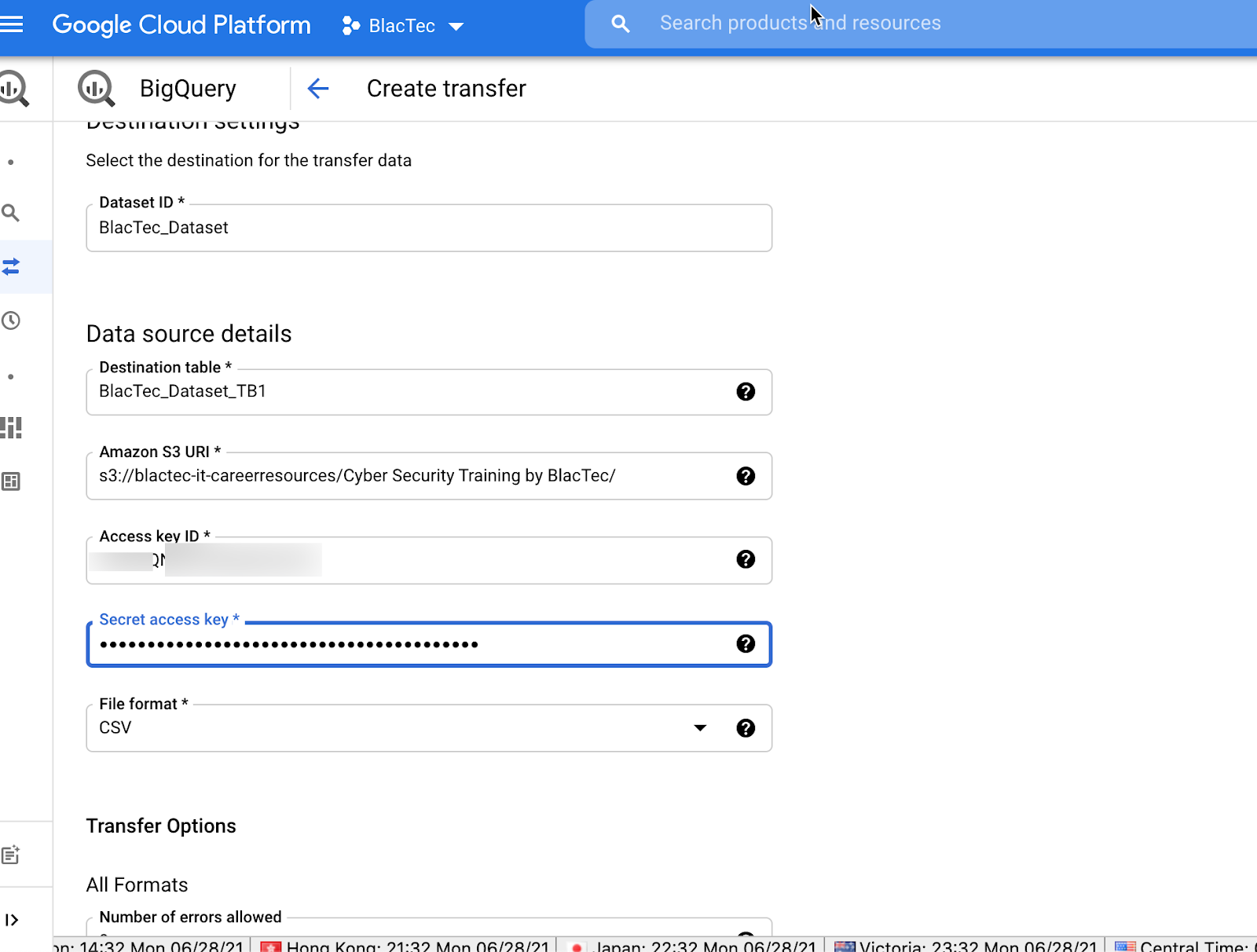
NAME Destination TABLE
-
Enter the source URI (Uniform Resource Identifier)
-
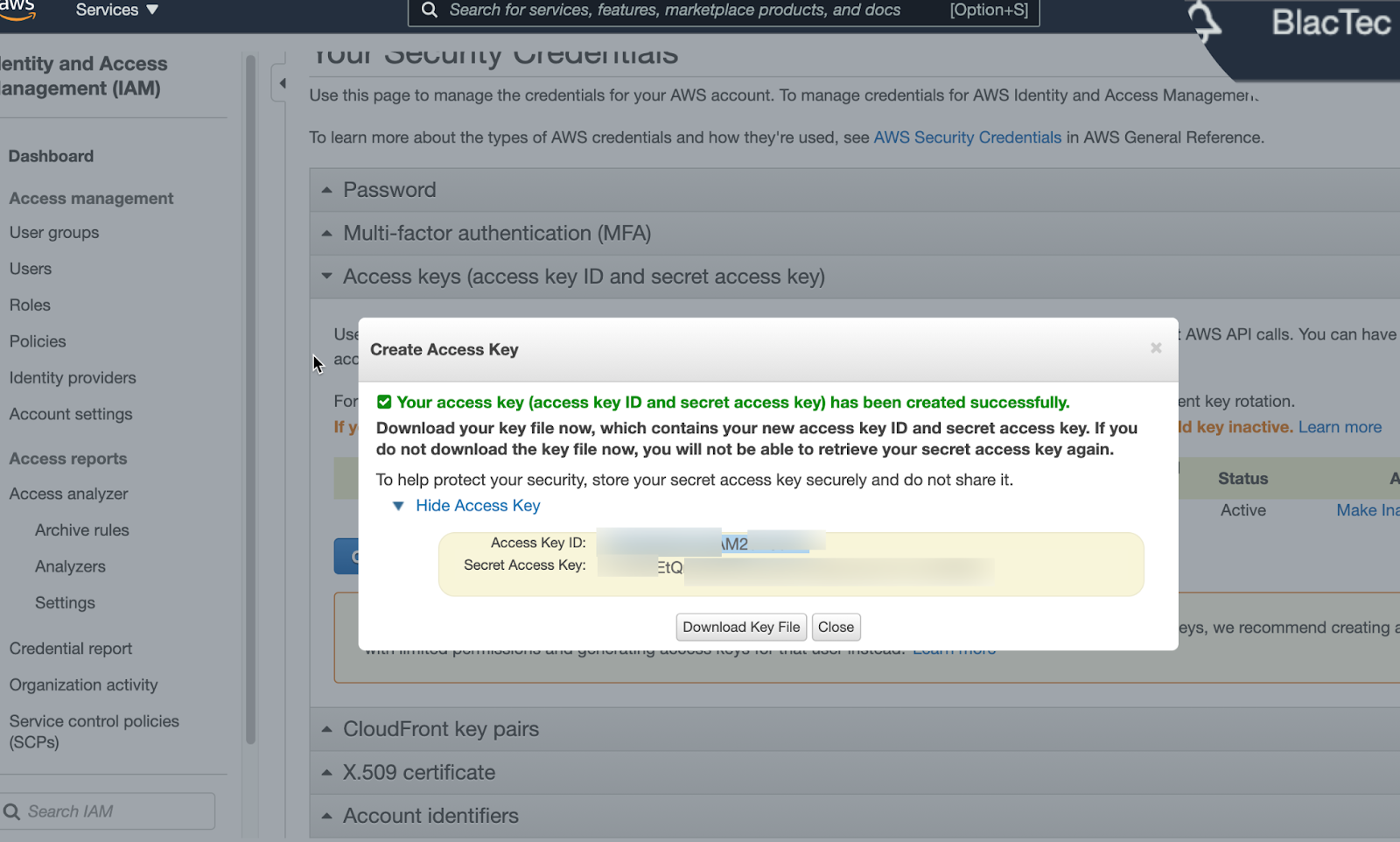
Enter Access Key for source as Required (Again, Personal Technical Acumen is MANDATORY!) Use Active Access Key ID’s / Secret Access Key’s Or Create New & store in secure repository for Org. Admins
-
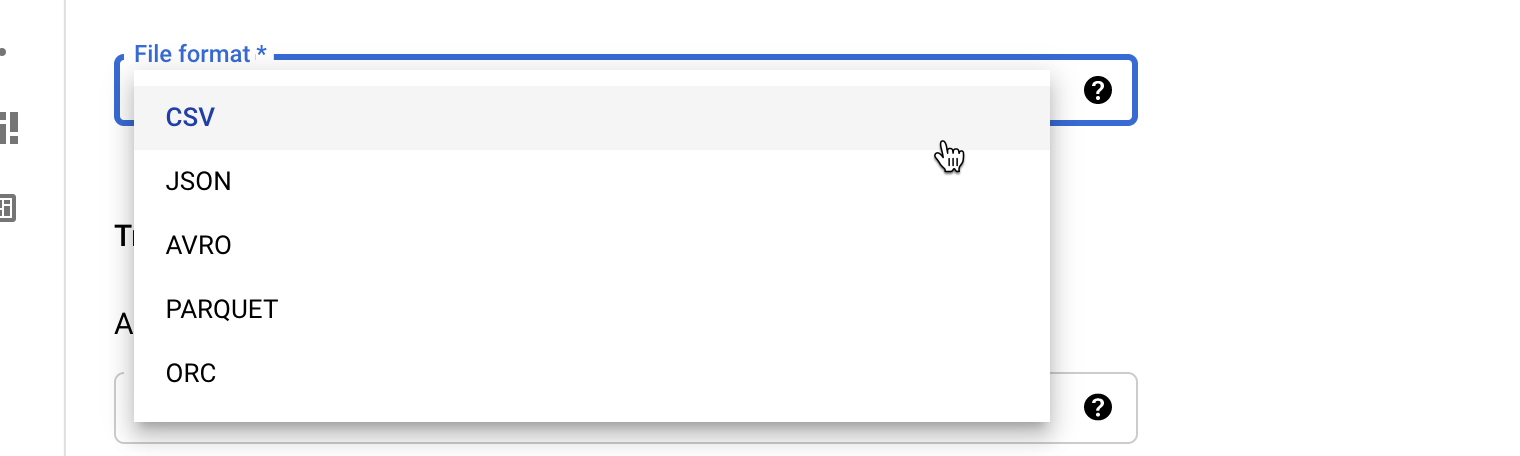
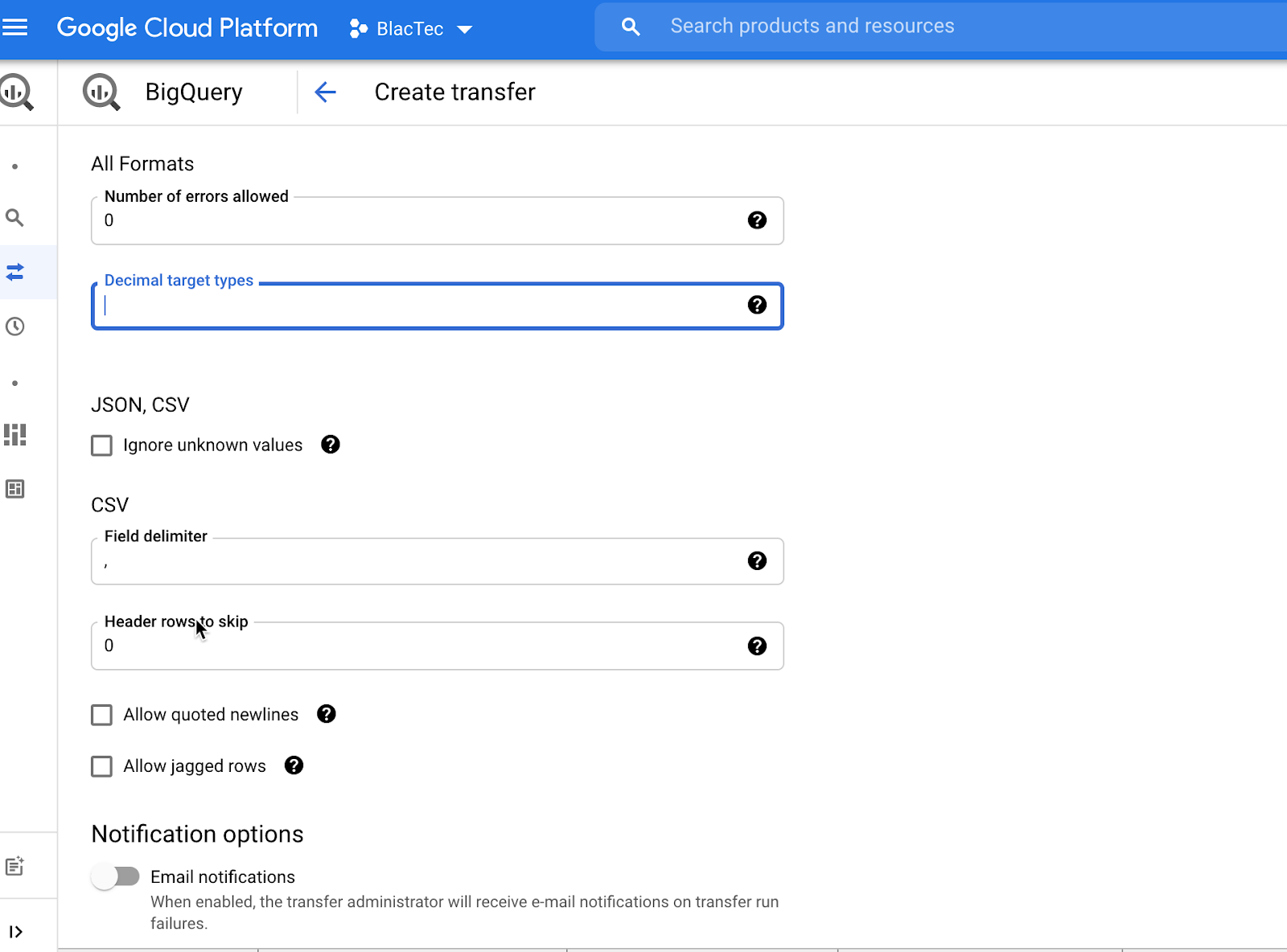
Choose File Format
-
Leave Defaults
-
Click Save
-
RUN ????????♂️xfer
-
Click “Ok”
-
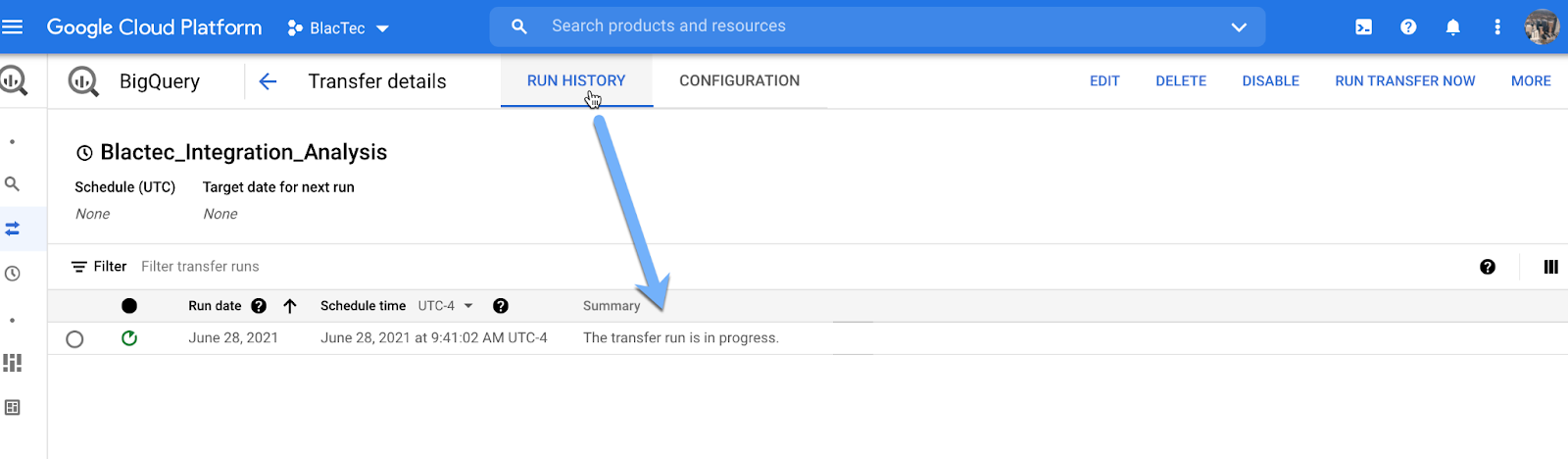
Check Status & Await Completion
-
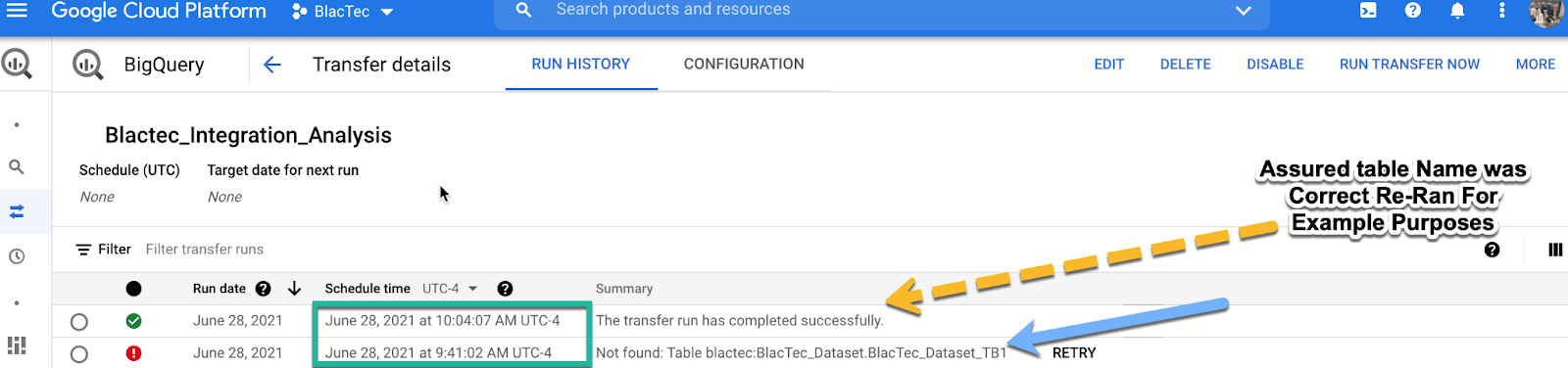
Check Table Names
-
Assure Resources that are intended to be integrated EXIST & The Access (ACL) includes entities request access to data |Analyse data formats to match destination as required|.
-
Check Properties within YOUR TABLE SCHEMA to Identify Field name, Type, Mode, Description, etc .



Will UPDATE as info/tech changes...